Google renforce les capacités visuelles de son modèle Gemini 3 Flash avec une nouvelle fonctionnalité baptisée Agentic Vision. Cette nouvelle fonctionnalité d’IA vise à rendre les réponses liées aux images plus fiables, en ancrant systématiquement l’analyse dans des preuves visuelles concrètes plutôt que dans de simples estimations probabilistes.
Une vision active au lieu d’une simple interprétation
Traditionnellement, les modèles d’intelligence artificielle traitent une image comme un instant figé. Lorsqu’un détail subtil échappe à leur compréhension — un numéro de série, un panneau éloigné ou une petite inscription — les modèles doivent souvent « deviner ». Avec Agentic Vision, Gemini 3 Flash adopte au contraire une démarche d’enquête visuelle active.

Le modèle fonctionne selon une boucle « Penser, Agir, Observer » : il commence par analyser la demande et l’image, élabore ensuite un plan d’action, puis exécute du code pour manipuler ou inspecter visuellement le contenu, avant d’intégrer ces nouvelles données dans son raisonnement final.
Zoom intelligent, annotations et calculs visuels
Concrètement, Gemini 3 Flash peut désormais recadrer une image, la faire pivoter, tracer des cadres ou ajouter des repères numériques pour fiabiliser ses réponses. Par exemple, pour compter les doigts d’une main, le modèle dessine automatiquement des cadres autour de chaque doigt afin d’éviter toute erreur de décompte.
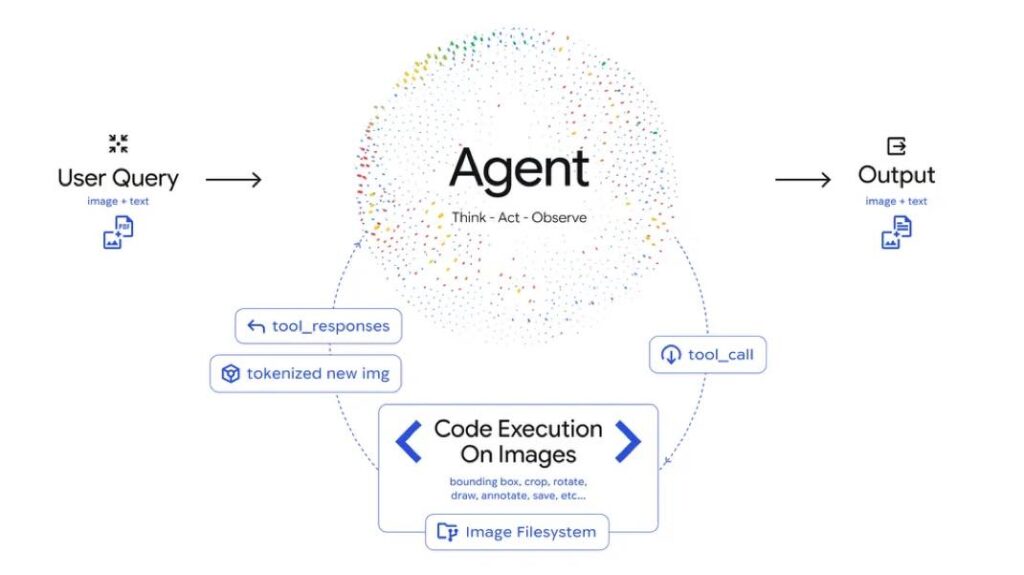
Agentic Vision est également capable d’exploiter des tableaux complexes ou d’effectuer des calculs visuels en s’appuyant sur un environnement Python déterministe. Cette méthode réduit fortement les risques d’hallucinations dans les tâches impliquant plusieurs étapes de raisonnement.
Un gain mesurable en précision et déjà disponible
Selon Google, cette nouvelle approche apporte une amélioration de 5 à 10 % sur la majorité des benchmarks liés à la vision artificielle. La fonctionnalité est en cours de déploiement dans l’application Gemini avec le modèle Thinking, et elle est d’ores et déjà accessible aux développeurs via l’API Gemini, Google AI Studio et Vertex AI.
À terme, Agentic Vision devrait intégrer davantage d’outils, comme la recherche web ou la reconnaissance inversée d’images, afin d’ancrer encore plus solidement les réponses dans le monde réel. Une évolution qui pourrait transformer la manière dont les modèles d’IA interprètent et exploitent les contenus visuels.





























")