Google annonce Gemini 3.1 Flash-Lite, son modèle d’intelligence artificielle le plus rapide et le plus économique de la gamme Gemini 3, disponible dès aujourd’hui en accès anticipé pour les développeurs via l’API Gemini dans Google AI Studio et sur Vertex AI pour les entreprises.

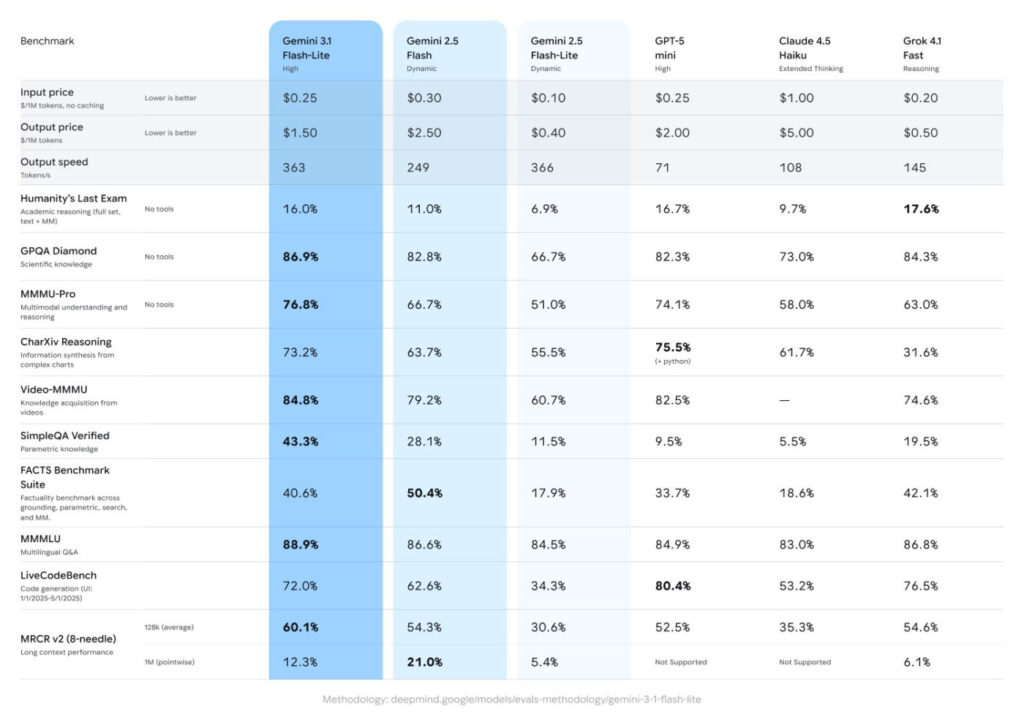
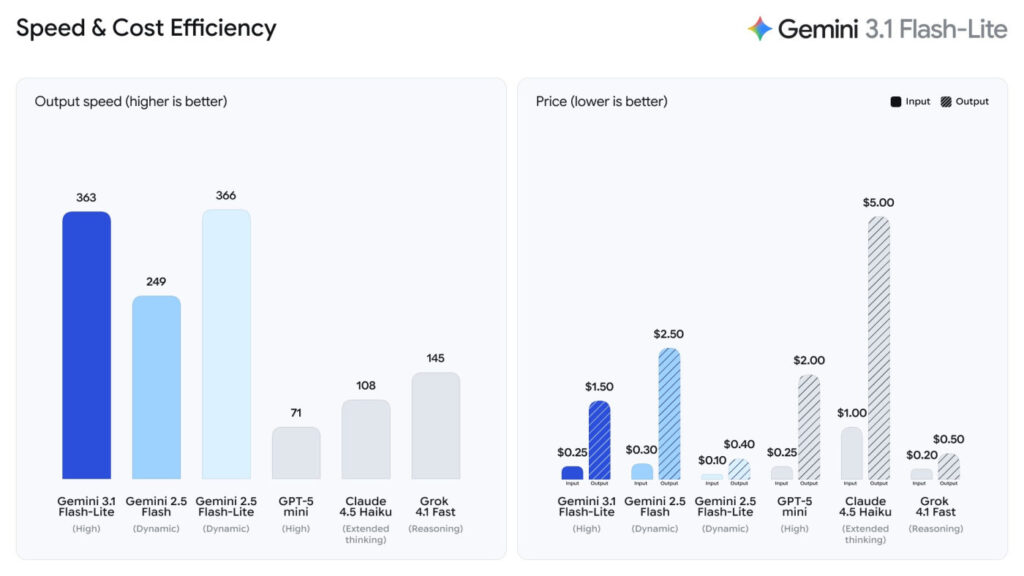
Le positionnement tarifaire est agressif : 0,25 $ par million de tokens en entrée et 1,50 $ par million de tokens en sortie. À titre de comparaison, GPT-5 mini facture 0,25 $ en entrée mais 2,00 $ en sortie, Claude 4.5 Haiku avec Extended Thinking atteint 1,00 $ en entrée et 5,00 $ en sortie, et Grok 4,1 Fast se positionne à 0,20 $ en entrée et 0,50 $ en sortie. Gemini 2.5 Flash-Lite, le prédécesseur direct, affichait 0,10 $ en entrée mais seulement 0,40 $ en sortie.
Le rapport vitesse/qualité comme principal argument
Gemini 3.1 Flash-Lite atteint 363 tokens par seconde en vitesse de sortie selon le benchmark Artificial Analysis. C’est 2,5 fois plus rapide en Time to First Answer Token et 45 % plus rapide en débit de sortie que Gemini 2.5 Flash. Cela confirme l’avantage face aux concurrents directs : GPT-5 mini plafonne à 71 tokens/s, Claude 4.5 Haiku (Extended Thinking) à 108 tokens/s, et Grok 4,1 Fast (Reasoning) à 145 tokens/s. Seul Gemini 2.5 Flash-Lite (Dynamic) fait mieux à 366 tokens/s, mais à un tarif en sortie quatre fois inférieur.
Sur les benchmarks de qualité, Gemini 3,1 Flash-Lite s’impose dans la grande majorité des tests face à ses concurrents de même catégorie. Il décroche 86,9 % sur GPQA Diamond (connaissances scientifiques), 76,8 % sur MMMU Pro (compréhension multimodale), 84,8 % sur Video-MMMU, 88,9 % sur MMLU multilingue et 43,3 % sur SimpleQA. Sur LiveCodeBench (génération de code), GPT-5 mini prend la tête à 80,4 % contre 72,0 % pour Gemini 3.1 Flash-Lite. Sur Humanity’s Last Exam, Grok 4,1 Fast mène à 17,6 % contre 16,0 %. Le modèle affiche un score Elo de 1 432 sur le classement Arena.ai.
Des niveaux de réflexion configurables
Gemini 3,1 Flash-Lite intègre des niveaux de réflexion configurables directement dans Google AI Studio et Vertex AI, une fonctionnalité qui permet aux développeurs de doser le niveau de raisonnement selon la nature de la tâche. Pour les usages à haut volume où le coût prime (traduction, modération de contenu ou tri d’images à grande échelle), le modèle peut fonctionner en mode minimal. Pour des tâches plus complexes nécessitant un raisonnement approfondi (génération d’interfaces, création de simulations ou agents multi-étapes), le niveau de réflexion peut être augmenté.
Google indique que des développeurs en accès anticipé sur AI Studio, Vertex AI, ainsi que des entreprises comme Latitude, Cartwheel et Whering utilisent déjà le modèle en production, soulignant sa capacité à traiter des entrées complexes avec « la précision d’un modèle de niveau supérieur » tout en respectant les instructions.
























")


")









